OpenAI, creator of the acclaimed ChatGPT, is behind Whisper, an automatic speech recognition (ASR) system, which it made open source in September 2022 to enable the project to develop more rapidly.
Whisper architecture
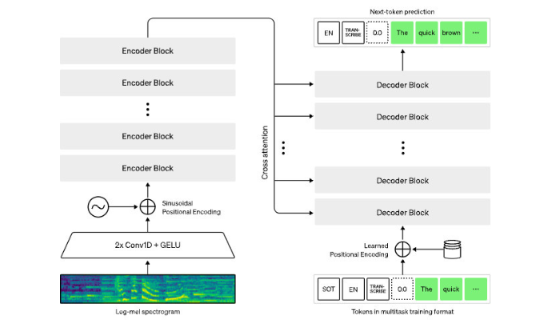
o Whisper uses a simple end-to-end architecture, in the form of an encoder-decoder Transformer.
o The workflow is as follows:
- Input audio is divided into 30-second segments.
- These segments are converted into log-Mel spectrograms which, simply put, mimic the way the human ear responds to different frequencies.
- They are then sent to an encoder.
- A decoder is trained to predict the corresponding text, with special tokens to perform tasks such as language identification, sentence-level timestamps, multilingual transcription and speech-to-English translation.